Lesser Known Features of PostgreSQL

Lesser Known Features of Postgresql
PostgreSQL, a renowned and reliable database system, is packed with a multitude of features that often go unnoticed. In this blog, we will shine a spotlight on these lesser-known gems, revealing their true potential. From fine-grained permissions at the column and row levels, enabling precise access control, to materialized views that optimize query performance by storing query results, and the clever "upsert" operation for streamlined data management, we will delve into the depths of PostgreSQL's hidden treasures. Whether you're a seasoned PostgreSQL user or just starting out, join us on this enlightening journey as we unlock the secrets of PostgreSQL's lesser-known features. Let's dive in!
You can download Postgres and pg-admin (tool to visualize data) from the below links:
Consider the below-created tables, for reference.
create a table if not exists "blogs"
(
id serial primary key,
title char(256) unique not null,
author_email char(100) not null,
description text,
created timestamptz not null default current_timestamp
);
create a table if not exists "reviews"
(
id serial primary key,
user_email char(100) not null,
rating_out_of_10 smallint constraint rating_range check (rating_out_of_10 between 0 and 10),
blog_id int, constraint fk_blogs_id foreign key(blog_id) references blogs(id),
created timestamptz not null default current_timestamp
);
Now, let's add some entries to the blogs and reviews table.
insert into blogs (title,author_email) values ('postgres', 'sahil@infocusp.com');
insert into blogs (title, author_email) values ('internal', 'sahil@infocusp.com');
insert into reviews (rating_out_of_10, user_email, blog_id) values (8, 'dummy@review', 1);
insert into reviews (rating_out_of_10, user_email, blog_id) values (10, 'fake@review', 2);
If you haven’t noticed yet, we have kept id serial, which is shorthand to assign auto-increment integer sequence as column type.
And we have a column created set to auto-populate current_timestamp on creation. So, after the above insert query, our data looks like this:
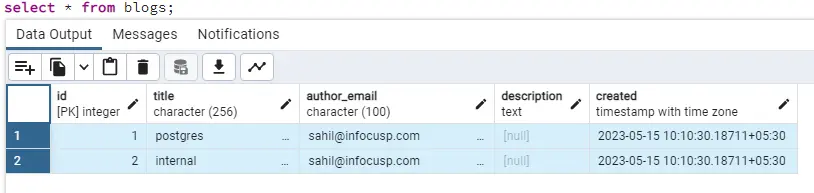
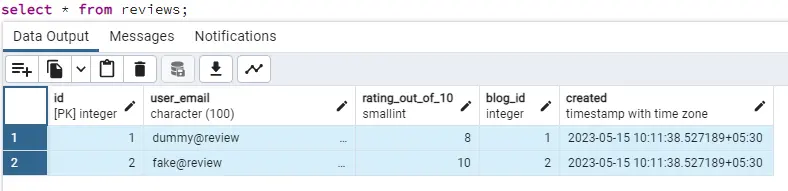
Enough of data entries, let’s now dive into the features.
Column & Row Level Permissions
Let’s start with permission-related features. So what if you want someone to have access to the blogs table but not to the reviews table? For that, we will create a restricted user who has only read access (select) for the blogs table.
create user restricted with password 'password';
grant select on blogs to restricted;
So now, if that new user tries to access data from the reviews table, they will get the error.
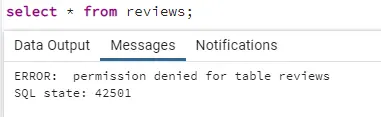
But now, if we want someone to even collect reviews data but not allow to see which user posted which review, we can set the permissions to access specific columns of the reviews table using:
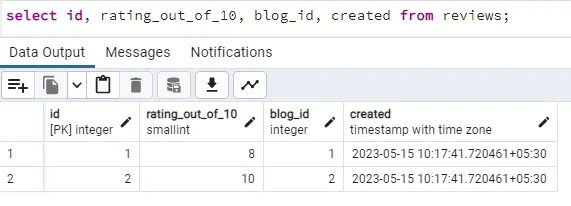
grant select (id, rating_out_of_10, blog_id, created) on reviews to restricted;
Restricted user will still get the same error as above if he tries the same query, select * from reviews, as we have not permitted for all columns. But, that user can fetch the data for the columns we have added access to using:
Now let’s enable and add row-level permissions using:
alter table blogs enable row level security;
create policy hide_internal_blog on blogs to restricted using (title!='internal');
With the above commands, we are not giving access to the blogs with the title internal to the restricted user we created earlier. So now, if we try to fetch the results with the restricted user, we won’t see the entry with the title internal.
 That’s how we can limit access to some roles based on column and row-level permissions.
That’s how we can limit access to some roles based on column and row-level permissions.
Materialized views
Materialized views allow you to create a snapshot of a query result and store it in a table (Unlike normal view, which does not store the result physically). This can be useful for improving the performance of complex queries that are frequently run, as the database can simply read the data from the materialized view instead of having to re-run the query each time.
Here’s an example of creating a materialized view:
create materialized view view_name AS
select user_email, rating_out_of_10, title from reviews join blogs on reviews.blog_id = blogs.id;
We can perform all the operations on materialized view same as the table
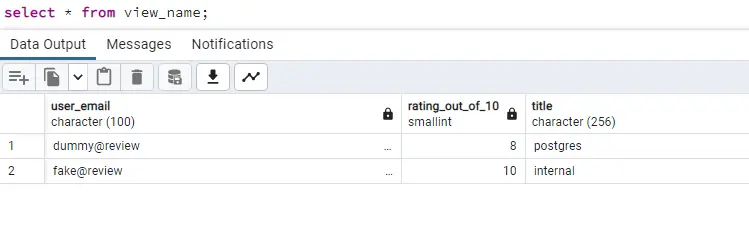
Let’s add one more review for our Postgres blog and see the data using the join query
insert into reviews (rating_out_of_10, user_email, blog_id) values (10, 'fake@review', 1);
select user_email, rating_out_of_10, title from reviews join blogs on reviews.blog_id = blogs.id;
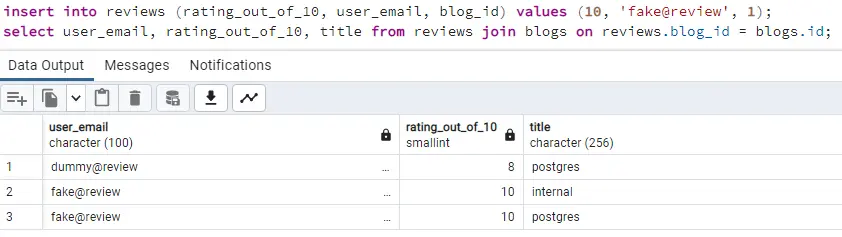
Now let's fetch the same data using our materialized view
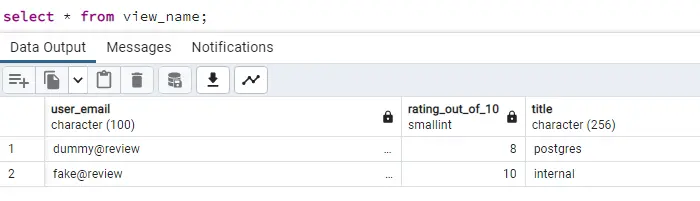
Wait, what! We don’t see the entry we inserted after the creation of the view.
One disadvantage of the materialized view is that you have to manually update the view on data changes in one of these tables. If we create a normal view we do not need to refresh as it executes the query on the fly.
We can refresh the materialized view using:
refresh materialized view view_name;
select * from view_name;
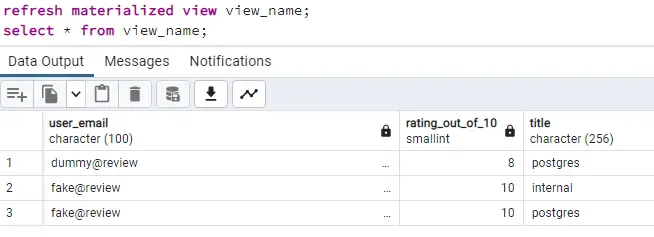
However, you can use triggers to update the materialized view on insertion, updation, or deletion from the source tables. And materialized views are extremely useful for the data which comes through complex queries and the underlying tables are not that frequently updated.
Upsert
Now let’s say we want to implement something like that there is a single blog on a single title, but we always update the table with the latest entry. For example, if tomorrow someone else is writing the blog on Postgres, we want to override the existing entry with new details.
Let’s see what happens if we directly use the insert query:
insert into blogs (title, author_email) values ('postgres', 'admin@infocusp.com');

To get the desired behavior, we will need 2 operation Find if the entry with the same title exists If exists, then run the update query, otherwise run the insert query
But instead, we can use the upsert, as the name suggests, it is the combination of update and insert.
Upsert is not the keyword; it is just a convention to call insert into on conflict syntax. So, here’s what our upsert query looks like:
insert into blogs (title, author_email, description) values ('postgres', 'admin@infocusp.com', 'dummy...')
on conflict (title) do update set author_email = excluded.author_email, description = excluded.description;
And this is how our data looks like after the above query

The ON CONFLICT clause is a new feature in PostgreSQL 9.5. It allows you to specify what should happen if the row already exists. In this case, we are telling PostgreSQL to update the row with the values from the EXCLUDED row.
The EXCLUDED row is a special row that contains the values that were passed to the INSERT statement. This allows us to update the row with the values that we passed in.
Always auto-generated/incremental keys
We have kept the id column as auto-increment in our blogs table. So let’s try what happens if we manually try to insert the id in the new entry.
insert into blogs (id, title, author_email) values (3, 'manual-entry', 'sahil@infocusp.com');
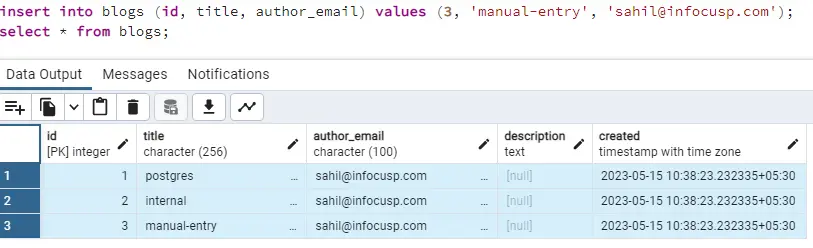
It worked fine. That’s great! But what happens when we try to insert a new entry without an id? Let’s find out.
insert into blogs (title, author_email) values ('auto-increment', 'sahil@infocusp.com');

It gives the error, because our sequence had value 2 after the initial data entry, and then we manually entered id as 3. So, for this entry sequence counter will increase by 1 and try to insert 3 as id but it will fail as we have manually inserted that.
But if you run the same query again, it will work because the sequence counter is incremented even for the failed queries, so it will generate 4 as the id for the next run.
But to overcome this issue, we can use Always to force the id column to be populated by the counter and reject the manual inserts in that column. We can use it below:
alter table blogs alter id drop default, alter id add generated always as identity (increment 1 start 4);
insert into blogs (id, title, author_email) values (4, 'should reject this', 'sahil@infocusp.com');
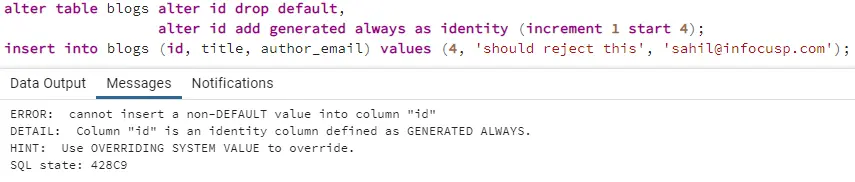
As you can see, if we manually try to insert id into the table, we will get an error. Same way, generated always can be used on the created column to prevent someone from entering the wrong values for that field.
Schemas
PostgreSQL schemas are a way to organize database objects, such as tables, views, and functions. They can be used to improve the readability and maintainability of your database and to control access to different parts of your database.
For example, you could create a schema for each application that uses your database. This would help to keep the objects for each application separately and would make it easier to find the objects that you need.
You could also use schemas to control access to different parts of your database. For example, you could create a schema for sensitive data and then only grant access to that schema to users who need to access that data.
Let’s add a separate schema named users and create a table profile in that schema, and also add an entry in that.
create schema if not exists users;
create table if not exists users.profile
(
id serial primary key,
name char(100) unique not null,
email char(100) not null,
designation char(50),
created timestamptz not null default current_timestamp
);
insert into users.profile (name, email, designation) values ('sahil', 'sahil@infocusp.com', 'SE');
Now, we can add a foreign key in our blogs table which will point to the profile table from the user's schema
alter table blogs add column author_id int constraint fk_blogs_authour_id references users.profile(id);
We can now update the column author_id to match the values from our new table from a different schema using
update blogs set author_id=(select id from users.profile where email=author_email);
And you can see now that the entries are updated in the blogs table and you can even use joins to fetch entire user details:
select title as blog_title, name as author_name from blogs join users.profile on blogs.author_id = users.profile.id;

This way, you can keep the data separate for different apps, and you can use the relationships across schema and manage access to each schema as needed.
Here are some of the benefits of using PostgreSQL schemas:
- Improved readability and maintainability: Schemas can help to improve the readability and maintainability of your database by organizing objects into logical groups.
- Improved security: Schemas can help to improve the security of your database by controlling access to different parts of your database.
- Improved performance: Schemas can help to improve the performance of your database by reducing the number of objects that need to be scanned when running a query.
In this blog, we've uncovered several lesser-known features of PostgreSQL that can bring added versatility and efficiency to your database management. From fine-grained access control to optimized query performance and simplified data manipulation, these hidden gems provide a wide array of benefits.
By harnessing these features, developers and database administrators can streamline workflows, fortify security measures, and unlock new possibilities in their PostgreSQL projects. So go ahead, explore these hidden features, and unlock the full potential of PostgreSQL in your projects!