
How Computer Vision Models have evolved in the last decade

From Perception to Imagination: The Deep Learning Revolution in Computer Vision
The deep learning revolution in computer vision has happened astonishingly fast. While the technology was already used in specialized settings, the shift to human-level perception and creative AI has taken place largely in the last decade. From the perception systems in self-driving cars to the generation of photorealistic art, these applications are now part of our daily lives. Join us as we explore this transformative decade, diving into the key architectural breakthroughs that solved fundamental training challenges and propelled us into an era where computers can not only see but also create.
Learning to See - The Evolution of Perception
It’s not so distant in the past where the question was “Can a computer see”? And the answer to this question went from “sort of” to a confident “YES!”. The tasks of computer vision perception on a high level are broadly categorized into classification, segmentation, and object detection. These three tasks form the bedrock of machine perception. Image classification asks, “What is the main subject in this image?” Segmentation asks, “Which pixels belong to which object?” and object detection answers, “Where are the objects, and what are they?”
Classification
Before 2015, the world of deep learning in computer vision was dominated by architectures like AlexNet and VGGNet. While these models pushed boundaries, they faced a critical limitation: as they became deeper, they ran into the vanishing gradient problem, which made it nearly impossible for the initial layers to learn. These roadblocks stalled progress in creating truly powerful, deep networks.
Resnet / DenseNet
ResNet (Residual Networks) solved this core challenge around 2015. Its central innovation was the skip connection, which allowed information to bypass layers and directly connect to later parts of the network. This simple architectural change solved the degradation issue and enabled the creation of ultra-deep models with hundreds of layers without sacrificing accuracy.
Building on this principle, DenseNet further optimized network connectivity. It connected every layer to every subsequent layer in a feed-forward fashion, fostering maximum feature reuse. This strategy resulted in models that were significantly more compact and computationally efficient than their ResNet predecessors.
Vision Transformers(ViT)
The Vision Transformer (ViT) was a radical architectural departure that addressed a fundamental limitation of CNNs: their difficulty in modeling long-range dependencies. Because CNNs rely on local receptive fields, they struggle to efficiently capture global relationships between distant parts of an image.
ViT uses self-attention to weigh the importance of all image components (converted into tokens) relative to each other. This allows it to directly and efficiently capture global relationships across the entire image in a single step. By demonstrating that this pure Transformer model could outperform state-of-the-art CNNs on large-scale tasks, provided there is a large amount of training data, ViT proved that self-attention was a viable and powerful alternative to convolutions for computer vision.
Segmentation
Before 2015, image segmentation relied on traditional computer vision methods like thresholding, edge detection, and region growing. These techniques struggled with complex images, as they lacked the ability to understand semantic context and recognize features robustly, a limitation later overcome by deep learning. The breakthrough came with CNN-based architectures like U-Nets and self-attention models like SWIN Transformers.
Unet Architecture
The U-Net architecture provided a major breakthrough in image segmentation, particularly for biomedical imaging where pixel-level precision is critical.
Its core design is the U-shaped encoder-decoder structure. While the encoder path learns high-level features by downsampling the image, the true innovation lies in its skip connections. These connections pass fine-grained spatial details directly from the contracting (encoder) path to the expansive (decoder) path. This allows the decoder to accurately recover the specific boundaries and locations of objects lost during downsampling, enabling it to create a highly accurate segmentation mask for every single pixel. This innovation made U-Net a cornerstone for precise localization tasks.

SWIN Transformers
While CNN-based models excelled, their reliance on local convolutions made it difficult to model long-range dependencies—a necessity for segmenting objects far apart in an image. The SWIN Transformer (Shifted Window Transformer) addressed this limitation by adapting the vision transformer architecture for better efficiency. It operates on small, non-overlapping windows to manage the high computational cost of large images. Its key innovation is the shifted window mechanism, which allows information to flow across these local windows in subsequent layers. This hierarchical approach effectively captures both local features and global context, ultimately enabling SWIN Transformers to outperform CNNs on high-resolution segmentation tasks and become a popular, powerful backbone for modern segmentation models.
Object Detection
Object detection is a core computer vision task that goes beyond simple image classification. Instead of just identifying the main subject of an image, it aims to find and draw a bounding box around every object of interest and classify what each one is. The evolution of object detection models has been a continuous race to improve accuracy and speed.
R-CNNs
R-CNN (Region-based Convolutional Neural Network) was a major breakthrough in object detection, combining traditional computer vision with deep learning. Its innovation was a multi-stage process that first used an algorithm to propose potential object locations. Each of these regions was then fed through a CNN to extract features. Finally, a separate classifier determined the object’s class. This pipeline was revolutionary because it was the first to successfully apply CNNs to the complex task of finding and classifying multiple objects in an image. While slow, it proved that a deep learning approach could significantly outperform older methods.
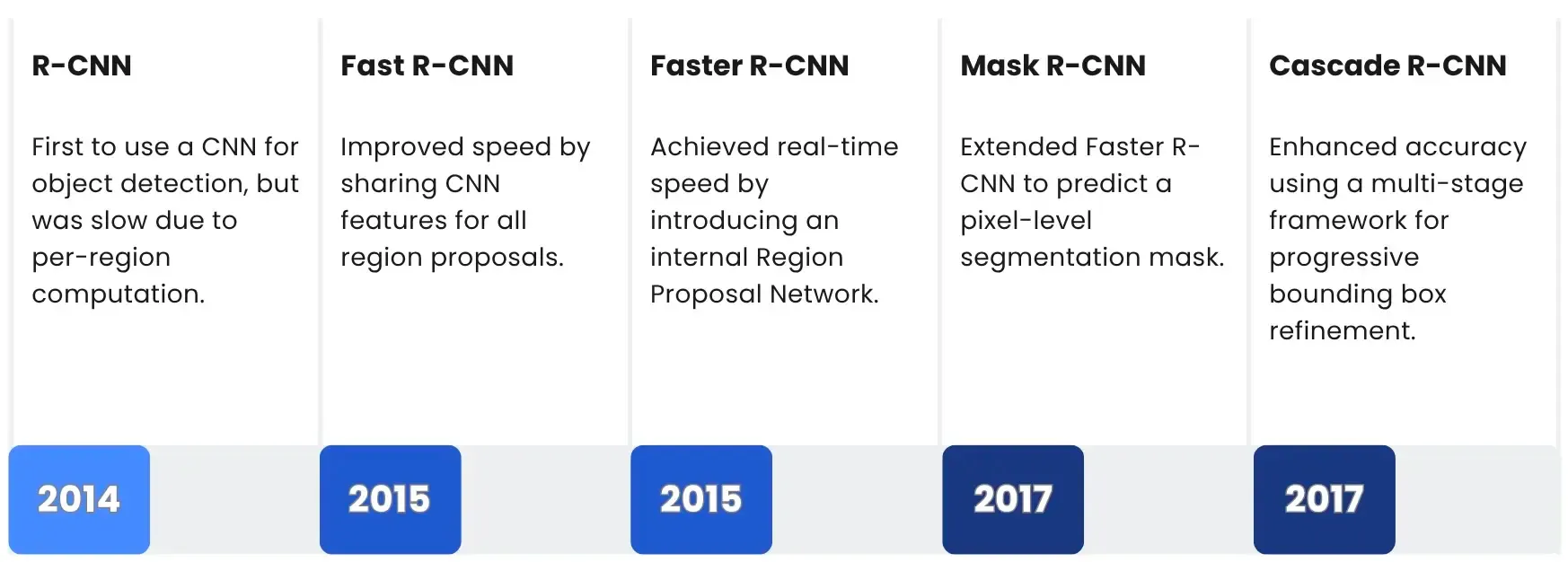
YOLO
While the R-CNN family established highly accurate object detection, it was fundamentally limited by its two-stage, sequential nature. The pursuit of real-time performance necessitated a new philosophy. The YOLO (You Only Look Once) family revolutionized the field by treating object detection as a single regression problem. This core novelty allowed a single neural network to predict bounding boxes and class probabilities simultaneously, completely eliminating the region proposal bottleneck and making detection incredibly fast and suitable for real-time applications. Since its inception, YOLO has evolved significantly. Modern versions are no longer limited to simple bounding boxes, transforming the model into a multi-purpose toolkit capable of sophisticated tasks like instance segmentation and pose estimation, solidifying its role as a versatile backbone for computer vision.
Learning to Think and Create: The Generative Era
Image to Text
The next frontier in computer vision is multi-modality, where models are trained to understand and relate different types of data, most notably images and text. The evolution of this field showcases a shift from sequential, task-specific architectures to a more unified, generalized approach.
CNN-RNN Models
Early multi-modal models for tasks like image captioning combined a Convolutional Neural Network (CNN) as an image encoder and a Recurrent Neural Network (RNN) as a text decoder. The CNN extracted high-level visual features, which the RNN then used to sequentially generate a natural language sentence.
While effective for its specific job, this traditional “encoder-decoder” had a key limitation: it was a task-specific, supervised model. It learned a direct, one-way mapping from image features to a caption, requiring massive, carefully labeled datasets. Consequently, these models lacked the ability to generalize or perform well on new, unseen vision-language tasks.
CLIP and ALIGN
A major paradigm shift occurred with models like CLIP (Contrastive Language-Image Pre-training) and ALIGN (A Large-scale ImaGe and Noisy-text embedding), both introduced around 2021. Instead of generating text from an image, these models learned to understand the relationship between images and text.
These models use a dual-encoder architecture, with one model for images and another for text. They are trained on a massive scale (billions of image-text pairs from the internet) using contrastive learning. The goal is to learn a shared embedding space where the vector representation of an image is close to the vector of its corresponding text, and far away from other random text descriptions. The breakthrough is their ability to perform a wide range of tasks “zero-shot”—without any additional training. This means you can give the model an image and ask it to identify an object from a list of words, or use a text query to instantly find a specific image. This unprecedented versatility and ability to generalize is the core reason why these models have become the foundation for the entire generative era of computer vision.

Image/Video Generation
While the previous generation of multi-modal models focused on comprehension, the cutting edge of computer vision now lies in creation. The fundamental challenge shifted from recognizing what an image is, to imagining and synthesizing an entirely new, high-fidelity image based solely on a textual description. This goal was pursued first by GANs, but it was the eventual breakthrough of Diffusion Models that truly unlocked the full potential of text-to-image generation, transforming simple prompts into complex, artistic, and photorealistic visuals.
Generative Adversarial Networks (GANs)
Introduced in 2014, Generative Adversarial Networks (GANs) were the first major breakthrough in deep learning-based image synthesis. Their novelty lies in a competitive, two-player game framework that is fundamentally different from other network architectures.
A GAN is comprised of two neural networks locked in a continuous battle:
- The Generator: This network acts as a forger, attempting to create highly convincing synthetic images from random input.
- The Discriminator: This network acts as a critic, whose sole job is to determine whether an image is a real photo from the dataset or a fake created by the Generator.
The two are trained simultaneously. As the Generator gets better at deceiving the Discriminator, the Discriminator is forced to become a sharper, more sophisticated critic. This constant, adversarial pressure drives the Generator to produce images of striking visual realism, pushing the boundaries of what machine-generated content could look like.
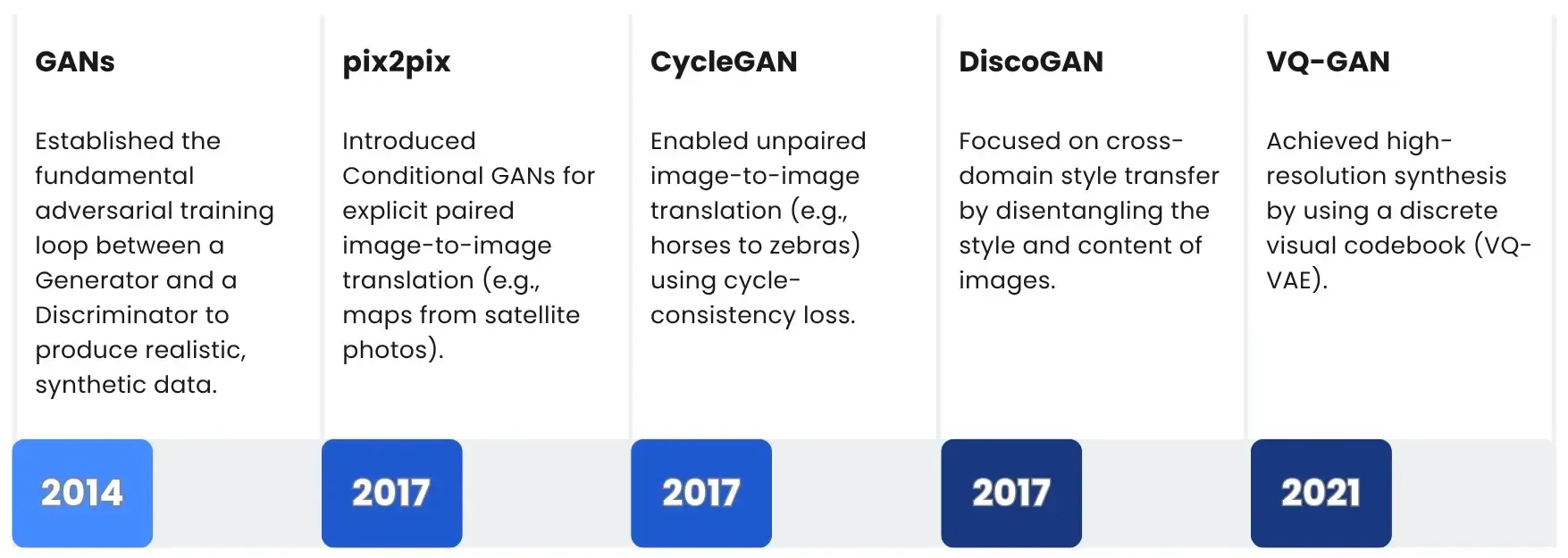
Diffusion Models
The instability and limited control of GANs led researchers to embrace a new architecture: Diffusion Models. These models completely reimagine the generative process by viewing it not as a single adversarial guess, but as a series of refined steps. The core idea involves training a model to reverse the process of adding noise. The model starts with pure noise and then, guided by a text prompt, meticulously denoises the image step-by-step until a high-fidelity image emerges. This fixed, iterative approach offers unparalleled stability and control, which was the primary limitation of GANs.
This stability led to massive achievements in models like DALL-E 2, Imagen, and Stable Diffusion (2022). They can produce images of unprecedented photorealism and coherence, mastering complex scenes and textures. Crucially, they excel at superior text-to-image alignment, accurately translating detailed, nuanced prompts into visual concepts. Today, diffusion models are the foundation for the generative era, enabling not just image creation, but also highly controllable editing and synthesis. These models also led to realistic video generation.
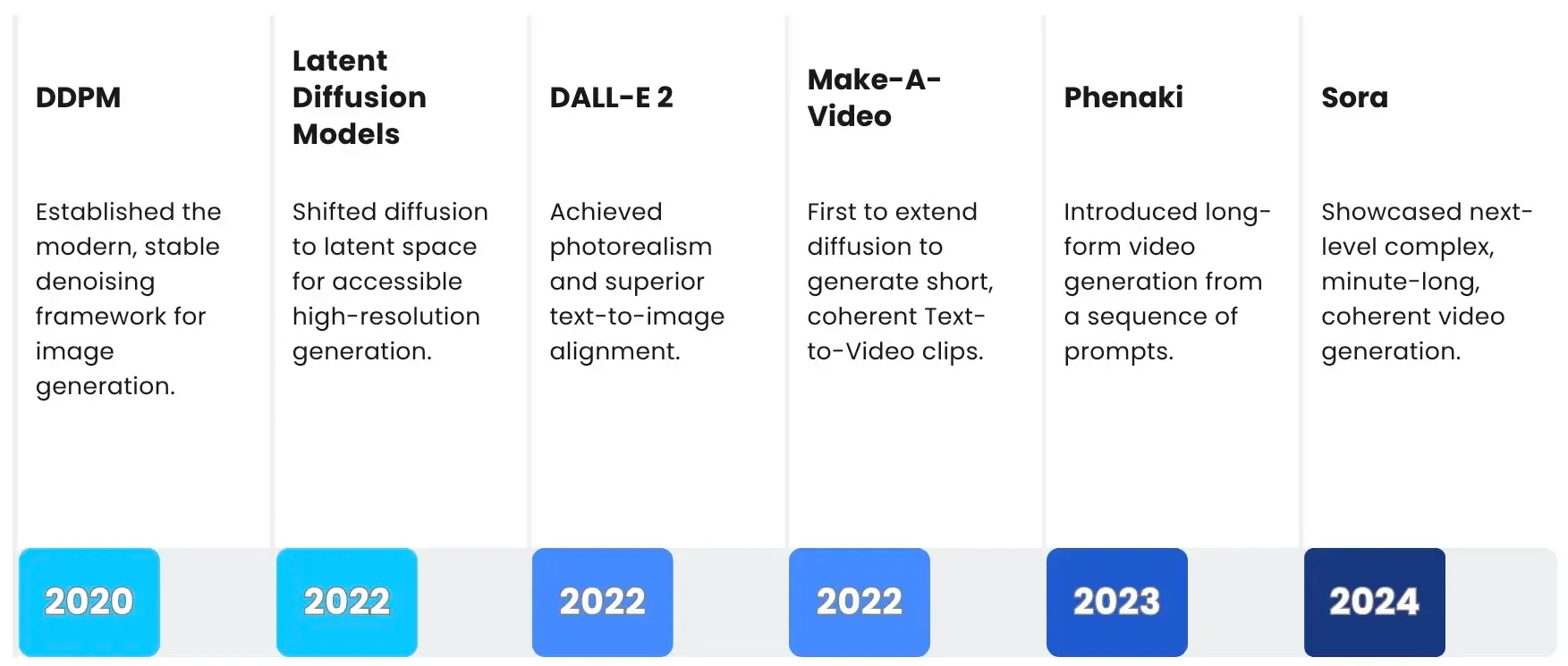
Learning to Imagine: The 3D World
While text-to-image and text-to-video models have mastered the creation of flat, 2D media, the ultimate frontier in computer vision is synthesizing and rendering the fully immersive 3D world. Traditional methods for building 3D scenes (like photogrammetry) required complex capture setups and long processing times. The next great breakthrough came from models that could generate novel views of a scene in the 3D space.
Neural Radiance Fields (NeRFs)
NeRF introduced a radical shift by discarding traditional 3D models like polygons and meshes. Instead, it uses a small, fully connected neural network (an MLP) as an implicit representation of the entire scene. This network functions as a sophisticated look-up table: when given a point’s exact 3D location (x,y,z) and the camera’s viewing angle, the network outputs the corresponding color (RGB) and transparency (σ). By combining the output of the network along millions of simulated light rays cast into the scene, NeRF achieves a level of stunning, view-dependent photorealism that was previously unattainable.
NeRF’s precision immediately proved useful for Virtual Reality (VR), telepresence, and advanced visual effects. However, this implicit approach came with a critical flaw: speed. The network had to be recalculated hundreds of times for every single pixel in every frame. This made rendering agonizingly slow, often taking seconds or even minutes per frame. This real-time bottleneck was the major challenge that needed to be overcome, driving researchers to seek a more efficient method that could achieve NeRF’s quality at interactive speeds, thus paving the way for 3D Gaussian Splatting.
Gaussian 3D Splatting
3D Gaussian Splatting (3DGS), introduced in 2023, was the breakthrough that solved NeRF’s critical problem of slow rendering speed. While NeRF used a time-consuming implicit network to calculate every point, 3DGS took a completely different, faster approach.
3DGS replaces NeRF’s implicit neural field with an explicit, point-based representation. The 3D scene is modeled using thousands or millions of small, colored 3D Gaussians (ellipsoids) floating in space. Each Gaussian explicitly stores its position, color, opacity, and shape. The core of its speed comes from its rendering technique: differentiable rasterization. Instead of NeRF’s slow, query-heavy ray marching, 3DGS projects these explicit Gaussians onto the image plane using highly optimized GPU operations—the same pipelines used in modern video games. This immediate speed boost, coupled with faster training and easier manipulation of the explicit points, has unlocked key applications: from enabling fluid Interactive VR/AR Content and creating Rapid Digital Twins to finally allowing the simple editing and animation of complex 3D assets within standard software pipelines. 3DGS has thus made photorealistic 3D scene representation practical for the first time.
The last decade has seen computer vision evolve through revolutionary leaps, moving far beyond simple image classification. We started with architectural breakthroughs that solved fundamental training barriers, allowing for the success of truly deep networks. This led to sophisticated systems for understanding pixels and accurately locating objects in real-time. The field then generalized, creating a shared understanding between vision and language which directly fueled the Generative Era. Today, with major advancements in generative modeling and the shift to high-speed 3D fidelity, computer vision has gone from merely analyzing the world to synthesizing photorealistic images, videos, and interactive 3D environments. This progression has set the stage for a future where digital content is not just consumed, but effortlessly and realistically created.



