Apache Airflow 101
In the fast-paced world of data engineering, keeping your workflows in sync is like conducting a digital symphony. That’s where orchestration tools come in – and Apache Airflow is one of the standout performers. But beyond the buzz, what is Airflow really all about, and how do you get your hands on the baton? Let’s unpack it from the ground up.
What is Airflow?
Apache Airflow is a flexible, open-source framework designed to let you build, schedule, and keep an eye on your data workflows. It transforms complex pipeline management into a streamlined, programmable experience, giving you full control from start to finish.
Think of it as a workflow orchestrator: you define tasks (like pulling data, cleaning it, storing it, sending a report), and Airflow handles when and how each task runs. It doesn’t process data itself – it just tells each part when to play its role, like a conductor in an orchestra.
Why use Airflow?
-
Automation: Run your workflows automatically – on a schedule or when triggered.
-
Visibility: Monitor task status easily with a clean web UI.
-
Scalability: Handles everything from simple jobs to complex pipelines with hundreds of tasks.
-
Modularity: Write workflows as Python code (DAGs), making them reusable and versionable.
-
Integration: Works smoothly with AWS, GCP, Azure, and other tools via operators and hooks. Example: uploading a file to AWS S3, triggering BigQuery jobs etc.
-
Parallel Execution: Efficiently runs multiple tasks in parallel using available workers.
Architecture
Airflow is made up of several core components that work together to define, schedule, and execute workflows. Here’s how they fit together:
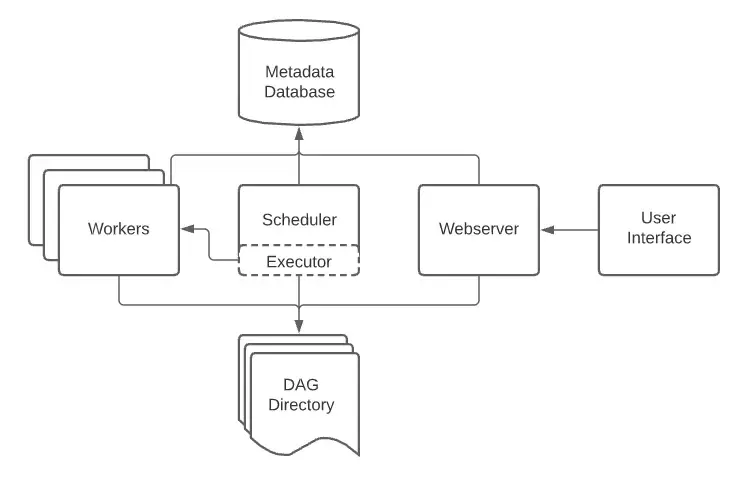
🧠 1. Scheduler
The Scheduler is Airflow’s brain. It reads DAGs, checks task schedules, and decides what to run when. Think of it like your workflow’s calendar assistant.
⚙️ 2. Executor
The Executor actually runs the tasks. It can do this:
- On the same machine (LocalExecutor)
- On distributed workers (CeleryExecutor / KubernetesExecutor)
The Scheduler delegates → the Executor executes.
🌐 3. Web Server (UI)
The Airflow Web UI is your control room. It’s clean, intuitive, and super helpful. You can do many things in UI like:
- View DAG structures
- Monitor task status
- Trigger or re-run tasks
📦 4. Metadata Database
Everything runs through this Metadata DB – it’s the central source of truth. Airflow uses a relational DB (like PostgreSQL/MySQL) to store:
- DAG definitions
- Task run histories
- Scheduling info
💻 5. Workers (for distributed setups)
In scalable environments (e.g., Celery/Kubernetes), tasks run on separate worker nodes, enabling parallel execution across machines.
📂 6. DAG Directory – The Workflow Vault
When the Airflow Scheduler starts up, it scans the DAG Directory to discover new DAGs, parse them, and decide which tasks need to be run based on their schedule. For example this DAG directory is a path to a folder in GCS bucket if our airflow dags are hosted on GCP composer.
Core Concepts
DAGs / How does Airflow orchestrate workflows?
In Airflow, workflows are defined as DAGs, which stands for Directed Acyclic Graphs.
That might sound technical at first, but it’s just a fancy way of describing a set of tasks that are connected in a specific order – and that order doesn’t loop back on itself (hence “acyclic”).
DAG
- Directed: The workflow has a clear direction. One task runs before or after another.
- Acyclic: There are no cycles – meaning a task won’t end up calling itself again, directly or indirectly.
- Graph: It’s a collection of nodes (tasks) and edges (dependencies).
Task
- Each task in a DAG represents a single unit of work, like downloading a file, transforming data, or sending an email.
- The DAG defines how these tasks are connected – for example, “task B should only run after task A finishes successfully”.
Airflow uses this DAG to orchestrate the workflow deciding how your tasks are structured, when to run each task, what order to run them in, and how to handle retries, failures, and dependencies.
So when we say Airflow is a workflow orchestrator, what we really mean is: it manages and runs your DAGs, making sure every task happens at the right time and in the right way.
In code, a DAG is defined using Python. Here’s a super basic example:
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from datetime import datetime
with DAG(
dag_id="example_dag",
start_date=datetime(2023, 1, 1),
schedule_interval="@daily", # Run once a day
catchup=False
) as dag:
start = DummyOperator(task_id="start")
end = DummyOperator(task_id="end")
start >> end # Define the task dependencyThis defines a simple DAG that runs once per day and has two tasks: start and end, where end should only run after start finishes successfully.
Key things a DAG defines:
- Schedule: How often the DAG should run.
- Start date: When the DAG should begin scheduling.
- Tasks: What needs to be done, broken into steps.
- Dependencies: How tasks depend on each other.
It’s important to remember that a DAG doesn’t do any real work itself. It’s just a blueprint. The actual work happens in the tasks that the DAG organizes and runs.
Operators
If a DAG is the blueprint of your workflow, then Operators are the building blocks that define what each task does.
In Airflow, Operator is one of the ways to define a task. You can think of Operators like tools in a toolbox – each one is built for a specific kind of job.
What is an Operator?
An Operator is a predefined class in Airflow that performs a specific action. When you are instantiating an Operator, you’re actually creating a task in a DAG.
Types of Operators
| Action Operator (executes something) | Transfer Operator (moves data from one place to another) | Sensor Operator (waits for something) |
|---|---|---|
| BashOperator (Runs a shell command) | S3ToGCSOperator (To move data from S3 to GCS) | S3KeySensor (Waits for a specific file or key to appear in an S3 bucket) |
| EmailOperator (Sends an email) | LocalFileSystemToGCSOperator (To move data from local to GCS) | FileSensor (Waits for a file to exist at a specified local or mounted path) |
| PythonOperator (Runs a Python function) | S3ToRedshiftOperator (Transfer data from S3 to Redshift table) | HttpSensorAsync (Asynchronously waits for an HTTP endpoint to return a valid response) |
| … | … | … |
Hooks
In Airflow, Hooks act as bridges between your workflows and the outside world – whether it’s a database, cloud service, API, or another external system. They handle the behind-the-scenes connections, so your pipelines can talk to other platforms without breaking a sweat.
While Operators define what a task does, Hooks handle how it connects to something outside of Airflow.
What does a Hook do?
A Hook knows how to:
- Authenticate with an external service (like AWS, GCP, or a SQL database)
- Establish a connection
- Run commands or queries (e.g., run a SQL query, upload to S3, call an API)
For example, the PostgresHook knows how to connect to a Postgres database and run SQL commands, the S3Hook knows how to talk to Amazon S3.
Here’s an example of using Hook in a custom PythonOperator:
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.operators.python import PythonOperator
def query_postgres():
hook = PostgresHook(postgres_conn_id="my_postgres_conn")
records = hook.get_records("SELECT * FROM users")
print(records)
query_task = PythonOperator(
task_id="query_users",
python_callable=query_postgres
)In this example:
- PostgresHook uses a connection defined in Airflow (my_postgres_conn)
- It handles authentication and connection pooling
- You don’t have to write raw connection logic—Airflow does it for you
Hooks Power Operators
Many built-in Operators (like S3ToRedshiftOperator, BigQueryOperator, etc.) use Hooks under the hood. As a developer, you’ll rarely use Hooks directly unless you’re writing custom logic – but it’s useful to know they’re doing the heavy lifting.
Hooks vs Operators
Both are python classes but they differ in their level of abstraction.
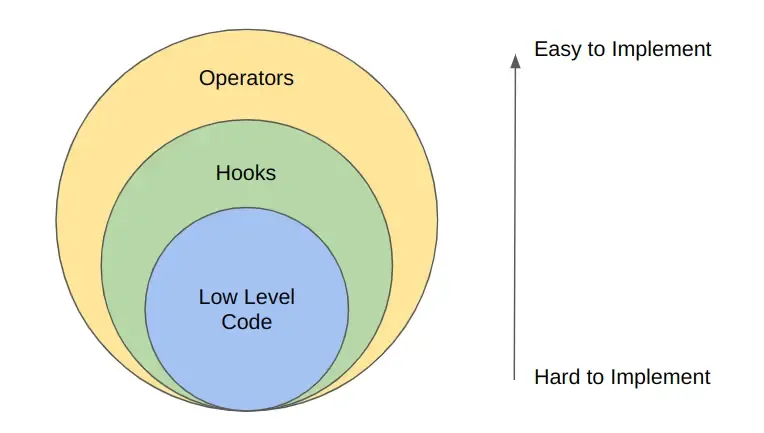
Which one should we use?
- If an operator is available to perform the task, use operator first.
- Then if a hook is available, use a hook.
- Then at last write your own code to accomplish the task.
Sensors
Sensors are a special type of Operator that are designed to do exactly one thing – wait for something to occur.
sensor_task = FileSensor(
task_id='check_for_file',
filepath='/path/to/file.txt',
mode='poke', # Default: 'poke'
# mode='reschedule' # Switch to reschedule mode
poke_interval=60, # Default: 60 seconds
timeout=600, # Default: (60*60*24*7) 7 days
soft_fail=True, # Default: False
deferrable=False, # Default: False
)In this example:
- FileSensor is the sensor operator that waits for a file named ‘/path/to/file.txt’.
- mode=’poke’, It checks for the file every poke_interval seconds (here, 60s); more details in next section.
- timeout, defines after how much time we should stop looking for the file & mark the task as failed or skipped (here, 10 mins).
- soft_fail=True, marks the task as skipped instead of failed if the file isn’t found in time
- deferrable=False, uses regular sensors instead of the new async deferrable ones (more details in following section).
Sensor Modes
- poke (default): The Sensor takes up a worker slot for its entire runtime.

- reschedule: The Sensor takes up a worker slot only when it is checking, and sleeps for a set duration between checks.

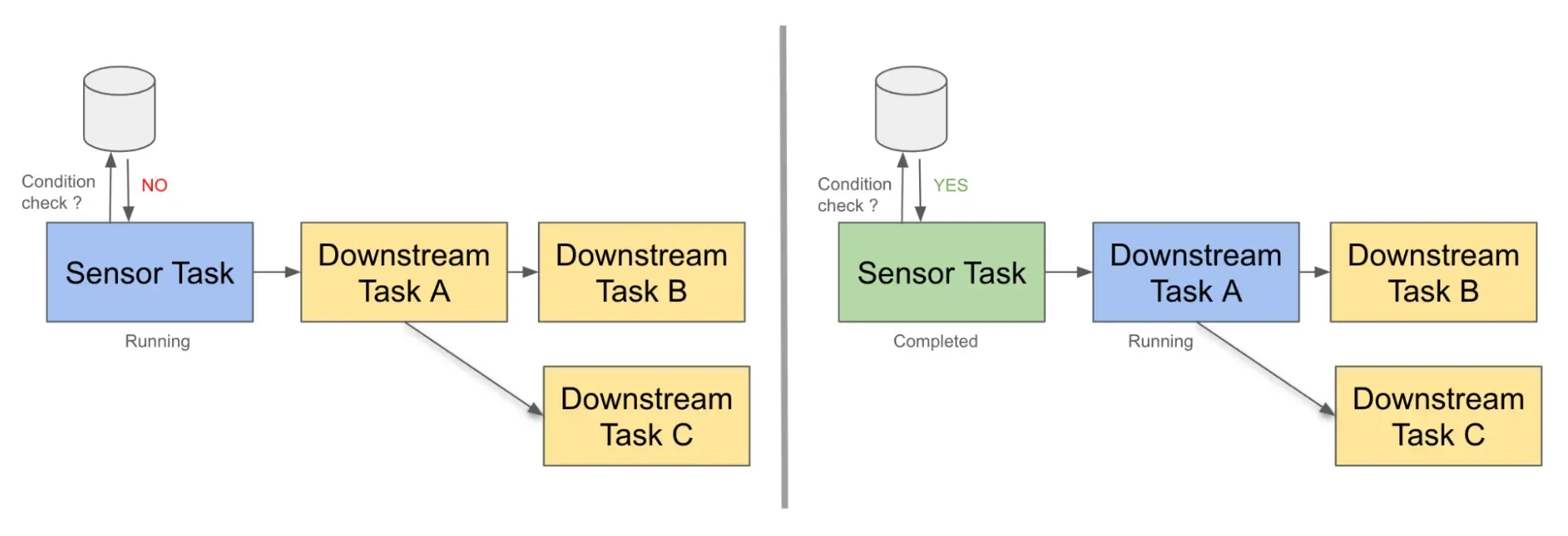
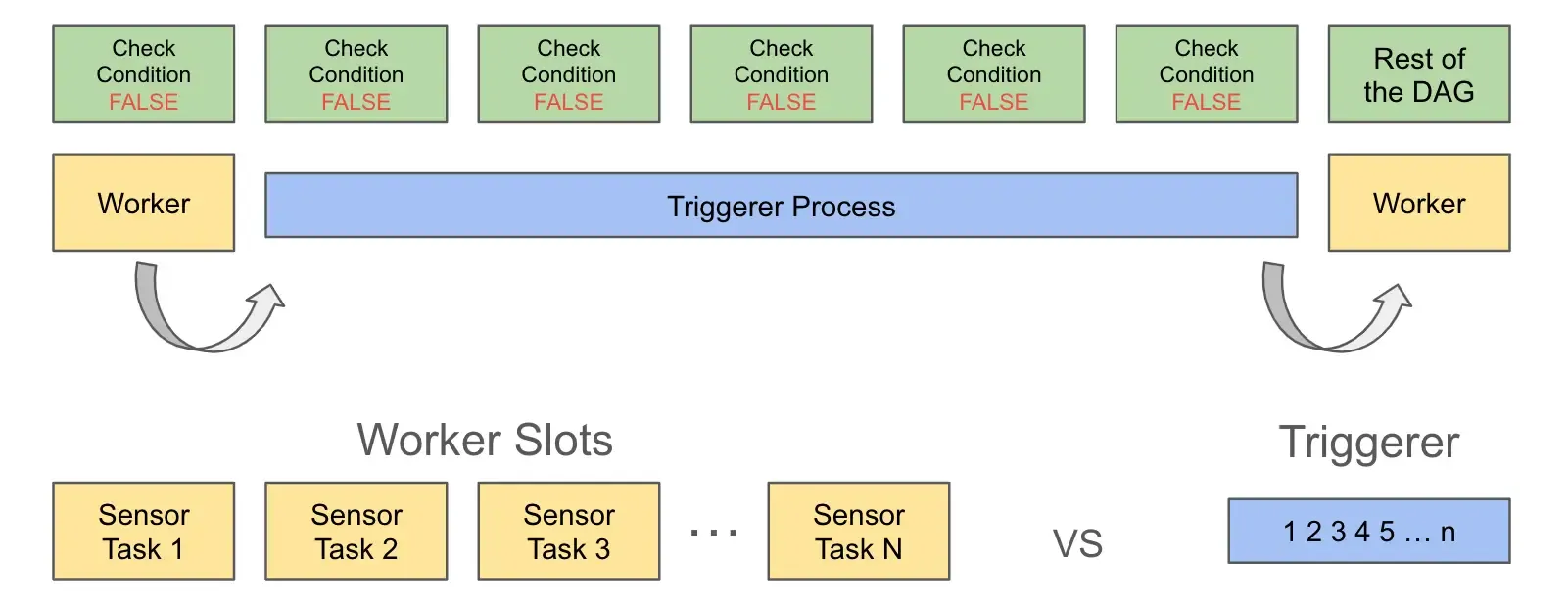
Deferrable Operators & Triggers
- When a task has nothing to do but wait, an operator can suspend itself and free up the worker for other processes by deferring.
- When an operator defers, execution moves to the triggerer.
- Tasks in a deferred state don’t occupy pool slots.
Branching and Triggers
In real-life data workflows, the path forward isn’t always linear. Sometimes, your DAG needs to make decisions – run different tasks depending on some condition. That’s where Branching and Trigger Rules come in.
Branching: Choosing the Path at Runtime
Airflow’s BranchPythonOperator lets you dynamically decide which downstream task(s) to run based on logic defined in a Python function.
Trigger Rules: Controlling Task Execution Logic
By default, a task will run only if all upstream tasks succeed. This is controlled by the trigger_rule parameter.
Here are a few commonly used trigger rules:
| Trigger Rule | Meaning |
|---|---|
| all_success | Run if all upstream tasks succeeded |
| one_success | Run if any one upstream task succeeded |
| all_failed | Run only if all upstream tasks failed |
| all_done | Run once all upstream tasks are complete (success or fail) |
| … | … |
Here’s an example which uses branching:
from airflow import DAG
from airflow.operators.python import BranchPythonOperator
from airflow.operators.empty import EmptyOperator
from airflow.utils.dates import days_ago
def choose_branch():
# Logic to decide the path
return "task_a"
with DAG(
"branching_example",
start_date=days_ago(1),
schedule_interval="@daily",
catchup=False
) as dag:
branch = BranchPythonOperator(
task_id="branching",
python_callable=choose_branch
)
task_a = EmptyOperator(task_id="task_a")
task_b = EmptyOperator(task_id="task_b")
final = EmptyOperator(task_id="final")
branch >> [task_a, task_b] # only one will run
[task_a, task_b] >> finalBranchPythonOperator decides which path (task) to run next. Only one branch is followed (task_a in this case), the other is skipped. Use this when your workflow needs to choose a path at runtime.
Here’s an example which uses triggers:
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from airflow.utils.trigger_rule import TriggerRule
from airflow.utils.dates import days_ago
with DAG(
"trigger_rule_example",
start_date=days_ago(1),
schedule_interval="@daily",
catchup=False)
as dag:
t1 = EmptyOperator(task_id="task_1")
t2 = EmptyOperator(task_id="task_2")
t3 = EmptyOperator(
task_id="task_3",
trigger_rule=TriggerRule.ONE_SUCCESS # Runs if either t1 or t2 succeeds
)
[t1, t2] >> t3By default, a task runs only if all upstream tasks succeed (all_success). trigger_rule=“one_success” lets task_3 run if at least one of task_1 or task_2 succeeds. Useful when merging branches or handling optional paths.
Catch up & Backfilling
Airflow’s scheduler is designed to run tasks on a defined schedule – daily, hourly, weekly, etc.
But what happens if you start a DAG today that was supposed to begin running a week ago? That’s where Catchup and Backfilling come in.
What is Catchup?
When catchup=True (which is the default), Airflow will automatically run all the past DAG runs between the start_date and now – one run per scheduled interval.
Example:
from airflow.models.dag import DAG
from pendulum import datetime
dag = DAG(
dag_id="example_dag",
start_date=datetime(2024, 1, 1),
schedule_interval="@daily",
catchup=True
)If you launch this DAG on April 1, 2025, Airflow will try to “catch up” by creating DAG runs for every day from Jan 1, 2024 to March 31, 2025. That’s 456 runs !
Disabling Catchup
If you don’t want to run all those past DAGs, you can turn off catchup:
catchup=FalseNow Airflow will only schedule runs from the current time forward.
What is Backfilling?
Backfilling is basically the manual version of catchup. You can trigger backfills using the CLI or UI.
Example via CLI:
airflow dags backfill -s 2024-01-01 -e 2024-01-10 example_dagThis runs your DAG for each day between Jan 1 and Jan 10, regardless of its current state.
Another way to backfill is to provide an end_date along with start_date in the dag settings when you initialize the DAG class like you just saw in the above example.
Why You Should Care
- Catchup can overload your system if you forget to turn it off on high-frequency DAGs.
- Backfilling is useful for reruns or historical data processing.
- Knowing when to use them (or not) helps you avoid surprises and manage Airflow more effectively.
Applications of Airflow
Apache Airflow is used across industries to automate and manage complex workflows. Here’s where it shines:
- Data Pipelines: Automate ETL/ELT workflows, data validation, and batch processing tasks.
- Machine Learning: Schedule model training, data preprocessing, evaluation, and deployment workflows.
- System Integrations: Move files, call APIs, and orchestrate services across cloud and on-prem systems.
- DevOps Automation: Perform system checks, manage database backups, and automate infrastructure tasks.
- Business Workflows: Power marketing campaigns, generate financial reports, and run scheduled business operations.
With features like dynamic workflows, scalable execution, and rich monitoring, Airflow is a go-to choice for building reliable, production-grade pipelines.
Real World Examples
Healthcare
Airflow can manage complex workflows for EHR data processing, regulatory compliance, and predictive diagnostics using ML pipelines. Reduces manual workloads by automating insights from patient data to improve care delivery.
eCommerce / Retail
Airflow can automate inventory tracking, customer behavior analysis, and personalized marketing pipelines to boost operational efficiency and customer engagement. Coordinate data across vendors and logistics for better demand forecasting and supply chain performance.